[ No 3 ]
OBFUSCATION DETECTION
Automatically detect obfuscated code and other state machines
Exploits

19 AUGUST 2021
Description
IDA 7.4+ Python3 plugin to automatically detect obfuscated code and state machines in binaries.
Implementation is based on IDA 7.4+ (Python3). Check out the following blog posts for more information on the Binary Ninja implementation:
As cited from the above blogs:
The goal is to develop heuristics that pinpoint code which shares similar characteristics to obfuscated code. Early in the reverse engineering process when we want to get a better overview over the binary, we can use these heuristics to spot interesting code locations that we can inspect manually. Even if these code locations are not obfuscated, they are still relevant for reverse engineers since they often implement complex dispatching routines, cryptographic algorithms or other important program logic.
One way to look at code obfuscation is that it tries to impede reverse engineering by artificially increasing the code’s complexity. Therefore, we can identify obfuscated code by looking for complex code, such as functions with large basic blocks or control-flow graphs. Another way to look at code obfuscation is that it tries to confuse reverse engineers by playing with their assumptions and analysis tools. This way, we can look for anomalies in our analysis tooling, such as overlapping instructions or meaningless disassembly.
If we want to apply such heuristics to large binaries (e.g., several hundreds of megabytes in size), they have to be efficient and provide a minimal analysis overhead. As a consequence, we rely on data points that are easy to obtain and heuristics that are cheap to compute.
In practice, it is useful to apply several heuristics independently: While different heuristics may find the same code locations, they may also find other locations since they look for different characteristics. In the following, we will get to know three such heuristics that accomplish the aforementioned requirements.
Control-flow Flattening
Intuitively, a control-flow graph represents all paths in a function that can be traversed during program execution. Such a graph has some nice mathematical properties that are valuable for any kind of code analysis, be it for compiler optimizations, for decompilation or for reverse engineering in general. Using dominance relations and loop detections (Graph Theory), we can automatically detect generic instances of control-flow flattening based on its underlying structure.
Complex Functions
Intuitively, large functions implement a complex program logic such as file parsing, network protocols, dispatching routines or cryptographic algorithms. If functions are large due to code obfuscation, they often contain dead code, (nested) opaque predicates or control-flow flattening.
Large Basic Blocks
Large basic blocks guarantee that a sequence of code is executed in a row. Often, they implement complex calculations, (unrolled) cryptographic algorithms or initialization routines. For obfuscated code, large basic blocks often contain dead code, initialize virtual machines or hide simple arithmetic calculations in complex arithmetic encodings.
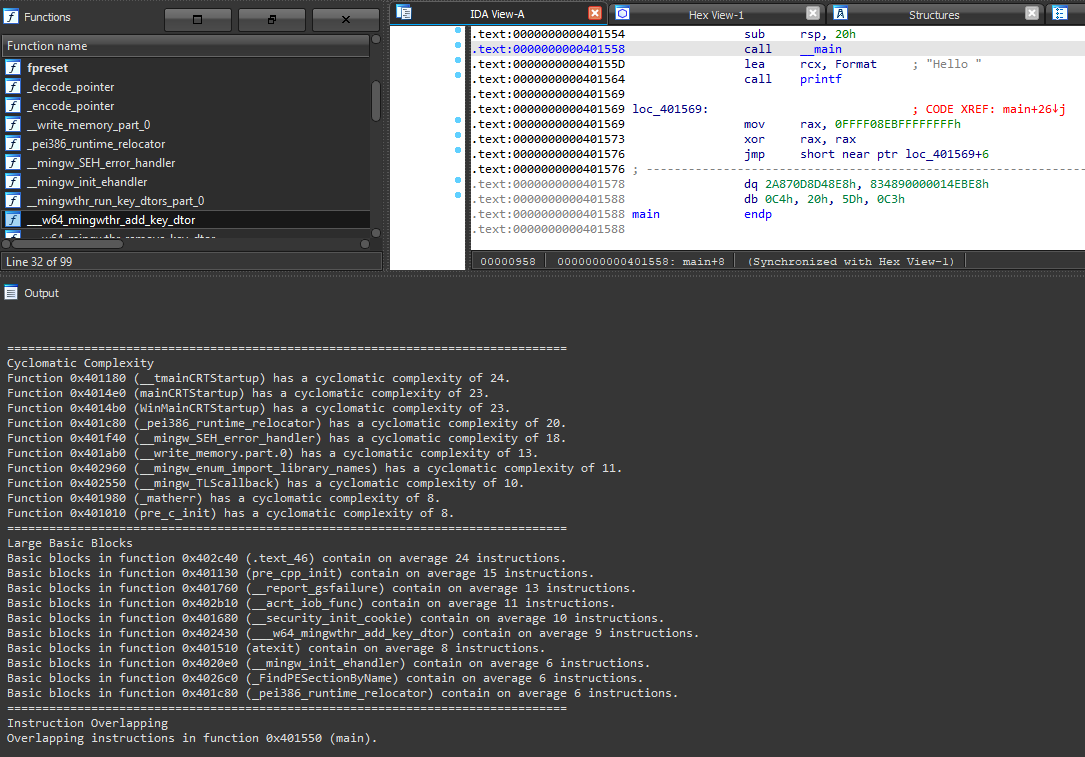
Instruction Overlapping
Up until now, the developed heuristics aimed at detecting complex code. However, sometimes code obfuscation tries to confuse disassemblers by introducing opaque control transfers to addresses that are in the middle of valid instructions. This way, the disassembler does not know how to proceed and build the control-flow graph, since two instructions overlap. In non-obfuscated code, this can also happen in cases where the disassembler mistakenly interprets data as code, therefore creates meaningless disassembly.
Evaluation
GUI Implementation
- Heuristic GUI analysis
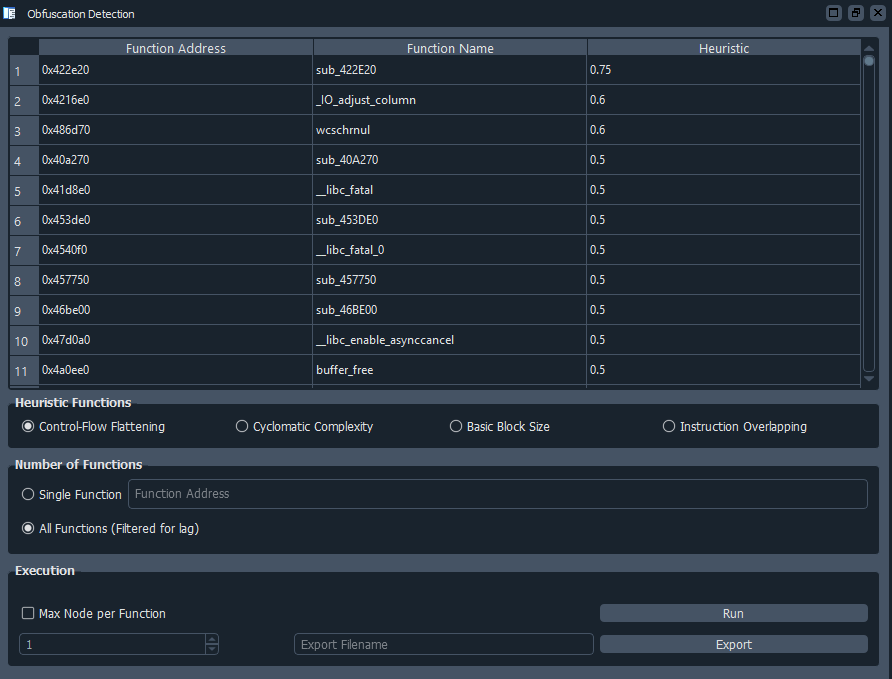
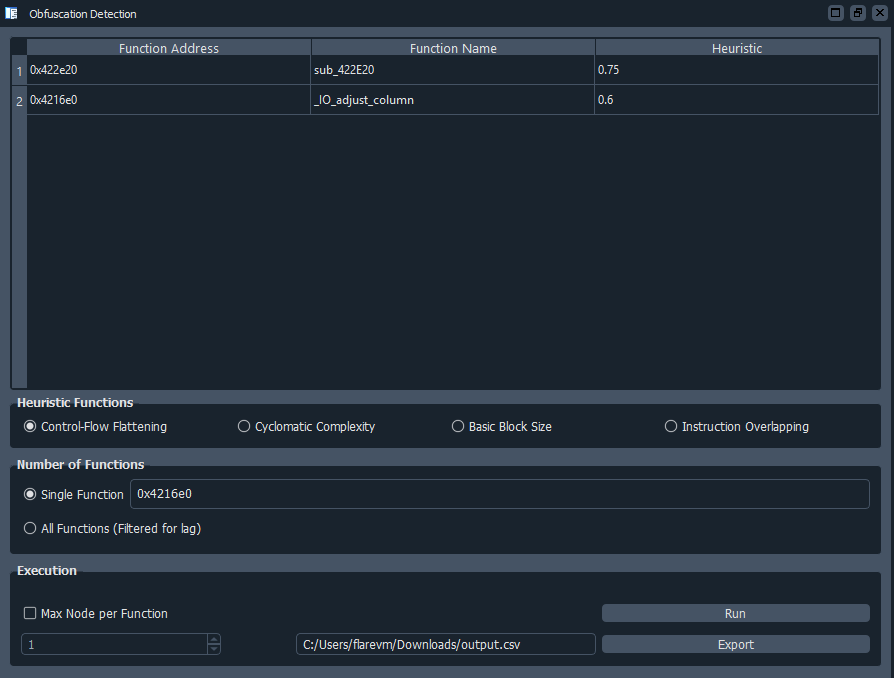
- Single function heuristic GUI analysis
CLI Implementation
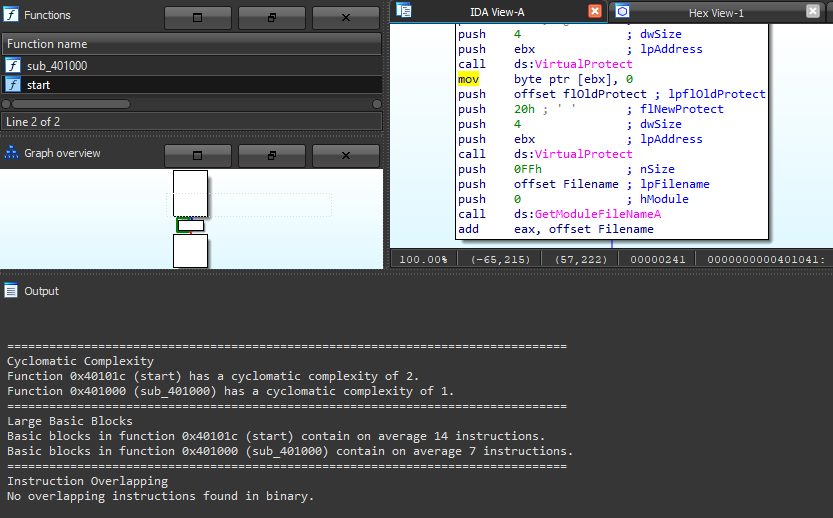
- A small binary with 2 scanned functions
- Resilience test using a large binary obfuscated using O-LLVM
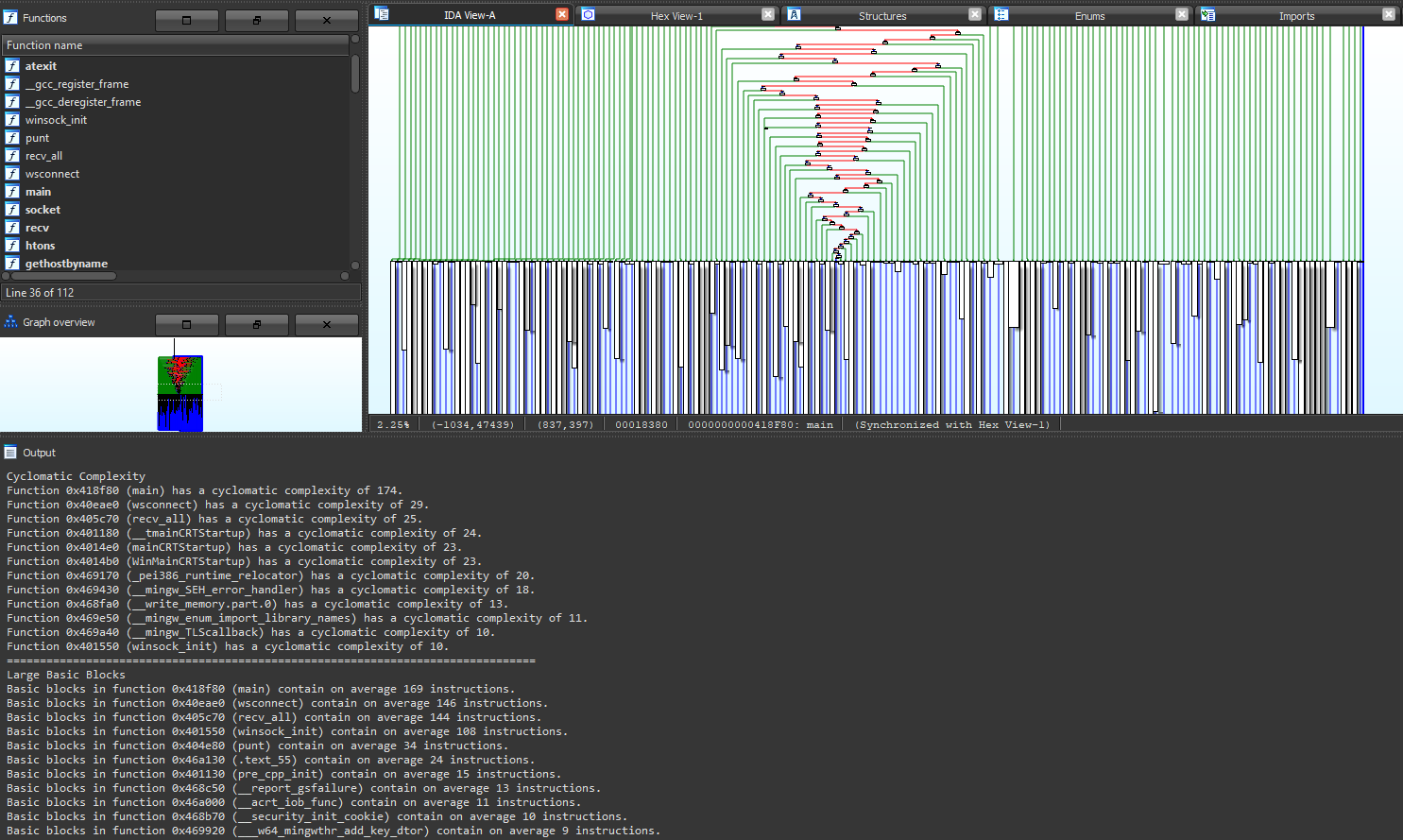
- Instruction overlapping heuristic detection
by Aaron Ti